前言
本文是Atlan公司(Gartner主动元数据方面的供应商)对外文档的内容梗概。文章标题为《Data Can Be Chaos. Work Shouldn’t Be.》,全文主要分享了“主动元数据如何帮助现代数据组织采用DataOps方式”这一话题。
全文介绍了三部分内容:
- 是什么:DataOps和Active Metadata是什么
- 怎么做:怎么实现DataOps,Active Metadata又发挥了什么功能
- 实际case:Active Metadata在行业的5个真实实践
正文
面对现实:传统的数据管理不起作用
75%的高管不相信他们组织的数据。考虑到如今公司在数据上花费了多少钱,这是一个大问题。更糟糕的是,首席数据官的平均任期只有2.5年,只有27%的数据项目真正成功。
- 75%的高管不相信他们组织的数据: HFS Research机构出具(Gartner排第一,HFS Research第二)。
- 任期2.5年
- 27%的数据项目真正成功
与此同时,数据的增长速度超过了这些公司所能跟上的速度。
数据团队变得比以往更加多样化——数据工程师、分析师、分析工程师、数据科学家、产品经理、业务分析师、公民数据科学家(不具专业背景或较为低级的数据科学家)等等。
他们使用的数据工具和基础设施越来越复杂。其中包括数据仓库、数据湖、Lakehouse、数据库、实时数据流、BI工具、笔记本、建模工具等。
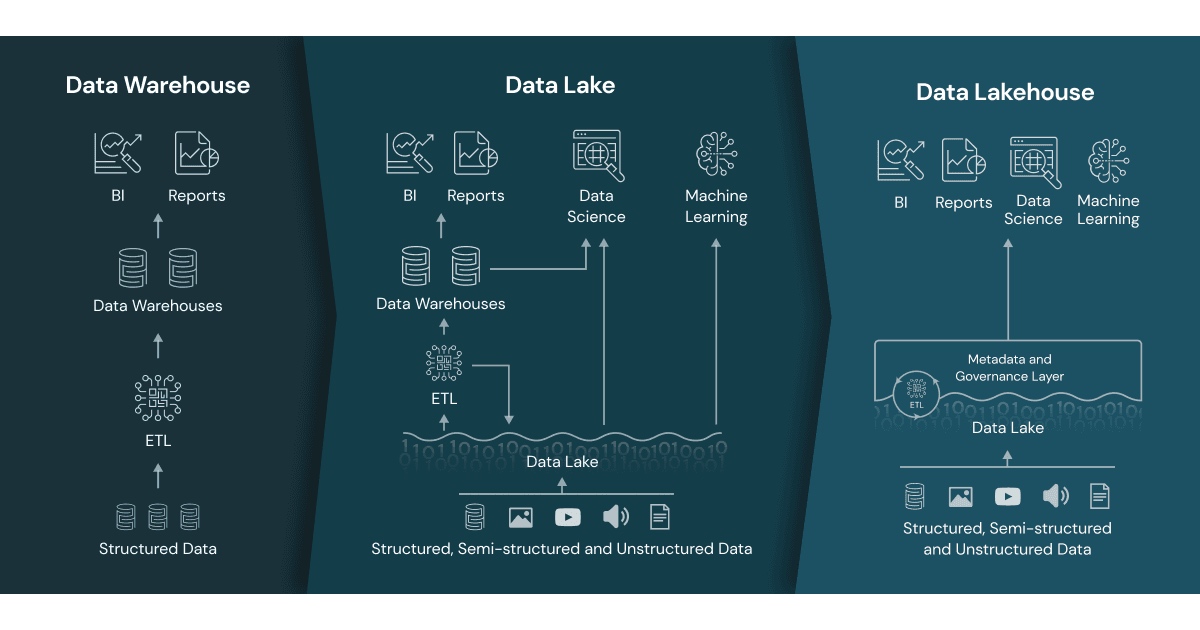
所有这一切导致了前所未有的数据混乱。(All of this has led to data chaos like never before.)
数据团队一般存在下面问题:
- 数据上下游间的协作问题:数据角色的多种多样使得数据链路的参与方越来越多,不同的参与方之间面临的上下协调沟通问题也越发凸显;
- 部落知识:部落知识是指公司内部不为人所知的任何不成文的知识。在小部分人中间口口相传约定俗成。该部分知识一般无法前置识别,大多数情况往往遇到实际场景才意识到;
- 英雄瓶颈:"Hero" Bottlenecks是一个在组织或团队中出现的现象,其中一个或几个关键的人(即"heroes")拥有大量的专业知识或技能,导致他们在许多任务和决策中都起着关键作用。这可能是因为他们有特殊的技能、经验或知识,使得他们在处理某些问题或任务时比其他人更有效。虽然这些"heroes"可能会带来很大的价值,但他们也可能成为瓶颈,因为他们的时间和精力是有限的,如果他们无法处理所有的任务,那么整个团队或项目的进度就可能会受到影响。这就是所谓的"Hero" Bottlenecks。

数据运营的兴起
2020年,Gartner发布了业界第一份关于DataOps的报告,表彰了一组DataOps领域的优秀供应商。从那时起,DataOps的地位不断提高,并变得更加主流。
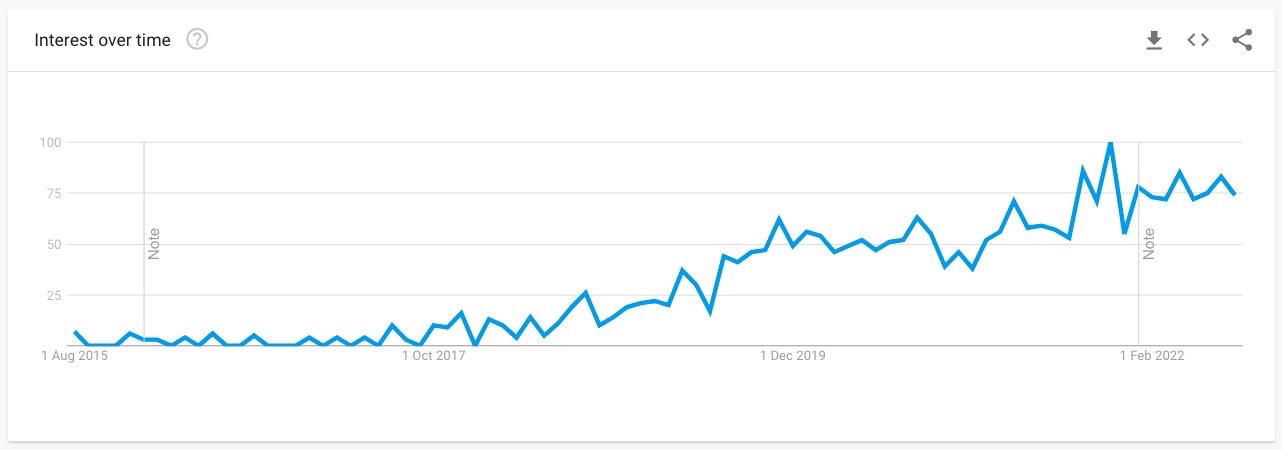
上图自2015年以来“DataOps”全球搜索的Google趋势数据。y轴显示“随时间变化的兴趣”,或搜索兴趣的标准化版本。100代表该术语在给定时间和地区的最高流行度。
Gartner在2022年技术成熟度曲线中预测,DataOps将在2-5年内全面渗透市场,并将这一趋势从曲线的最左侧转移到“期望膨胀的峰值”。随后,Forrester 于2022年6月23日发布了最新版本的关于数据目录的Wave报告。但他们没有像以前那样谈论“机器学习数据目录”,而是将该类别重命名为“DataOps的企业数据目录”——宣布DataOps成为主流。
DataOps到底是什么?
DataOps 是一种协作数据管理实践,专注于改善组织内数据管理者和数据消费者之间数据流的通信、集成和自动化。 DataOps 的目标是通过创建数据、数据模型和相关工件的可预测交付和变更管理来更快地交付价值。 DataOps 使用技术通过适当的治理级别来自动化数据交付的设计、部署和管理,并使用元数据来提高动态环境中数据的可用性和价值。[来源于Gartner Glossary]
关于DataOps,首先要了解的,也许是最重要的一点是,它不是一种产品。也不是一个工具。事实上,这不是你能买到的任何东西,任何试图告诉你其他情况的人都是在欺骗你。DataOps没有标准定义。然而,您会发现每个人谈论DataOps时都超出了技术或工具的范围。相反,他们关注沟通、协作、整合、体验和合作等术语。
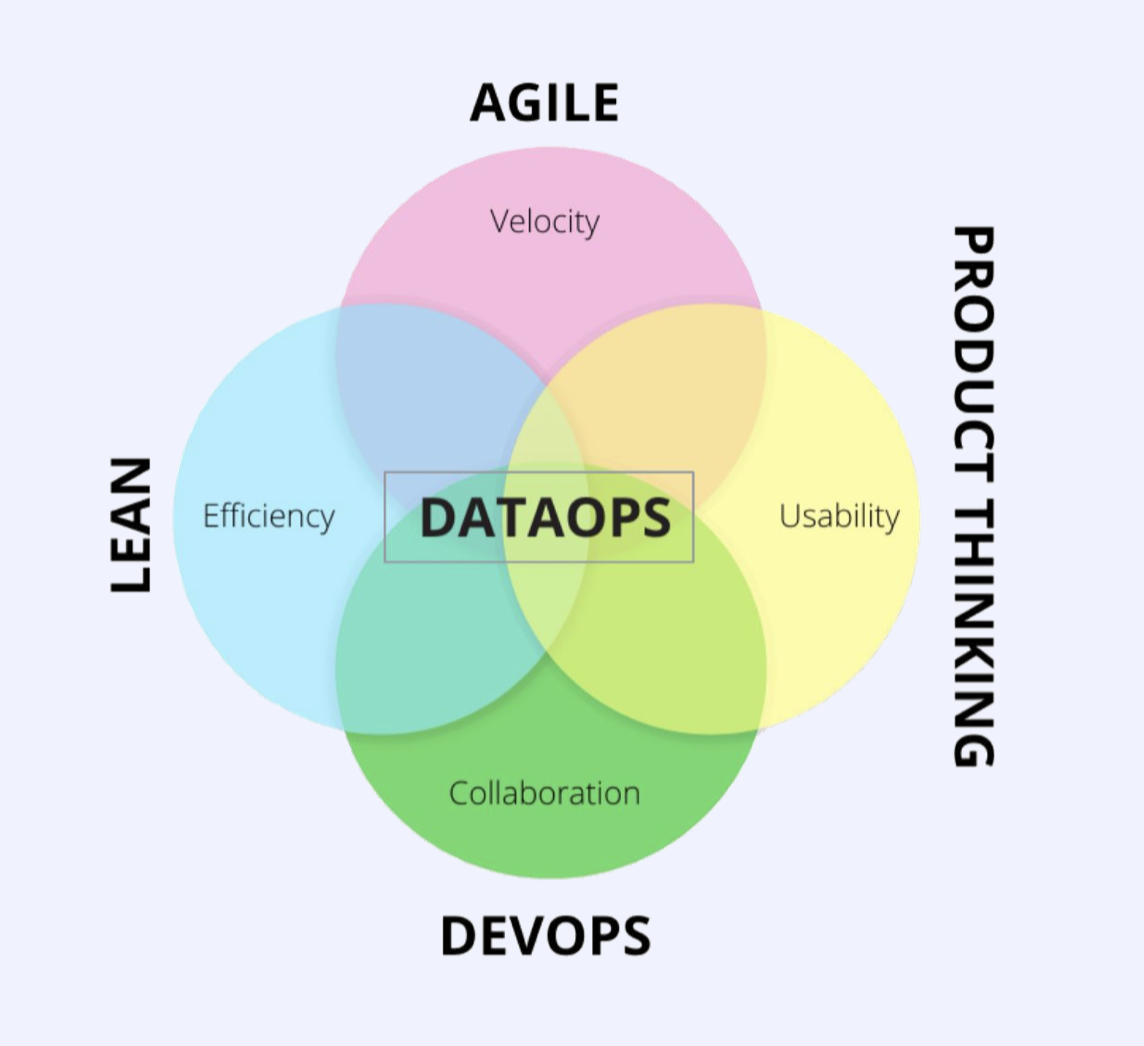
在我们看来,DataOps 实际上是将当今日益多样化的数据团队聚集在一起,并帮助他们跨同样多样化的工具和流程进行工作。其原则和流程可帮助团队推动更好的数据管理、节省时间并减少浪费的精力。将DataOps视为敏捷、精益、DevOps和产品思维的最佳部分,全部应用于数据管理领域。
- 敏捷:速度
- 精益:效率
- DevOps:协作
- 产品思维:可用性
DataOps方法如何帮助我们的团队敏捷性提高6倍并构建印度国家数据平台
在 Atlan,我们起初是一个数据团队,通过大规模数据项目解决社会公益问题。这些项目非常酷—我们有机会和联合国、盖茨基金会等组织一起参与影响数百万人的大规模项目。
但是在内部,生活却是混乱的。我们处理了所有可能的紧急情况,导致了漫长而令人沮丧的电话链和花费大量时间试图找出问题所在。我们破坏了信任,我们知道这种情况不能继续下去。
我们全心全意地解决这个问题,并齐心协力用新的工具和实践来解决这些问题。从其他最佳实践中汲取灵感,我们偶然发现了现在所称的DataOps。
正是在这段时间里,我们看到了正确的工具和文化可以为数据团队带来什么。混乱减少了,同样的海量数据项目变得更快、更容易,深夜的电话也变得异常罕见。结果,我们能够用更少的钱完成更多的事情。我们建立了印度的国家数据平台,由八名成员的团队在短短 12 个月内完成,其中许多人以前从未将一行代码投入生产。
后来,我们在DataOps文化准则中写下了我们的经验教训,这是一套帮助数据团队更好地合作、建立信任和协作的原则。
这就是DataOps的最终用途,也是它如今风靡一时的原因。它可以帮助数据团队不再将时间浪费在他们和他们喜欢做的工作之间无休止的人际关系和技术障碍上。在当今的经济中,任何节省时间的东西都是无价的。
DataOps文化密码
🤝 这是一项团队运动,协作是关键
数据团队非常多元化。数据科学家、分析师、工程师、业务用户等。所有不同的人,拥有不同的工具、技能和DNA。拥抱多样性,建立有效协作机制。
🗄将所有数据资产视为资产或产品
所有数据资产,从代码和模型到数据和仪表板,都是资产,都应该被视为资产。这样资产才易于发现、维护和重用。
🚀 优化敏捷性
随着业务需求的快速发展,数据团队需要领先一步,而不是被三个月的积压所淹没。不断衡量团队的速度,并投资于基础计划以缩短周期时间。
- 减少业务、分析师和工程师之间的依赖;
- 实现文档优先的文化;
- 将重复的工作自动化;
👥 创建信任系统
由于数据团队固有的多样性,很容易误解其他团队成员的角色。但这会造成信任危机——尤其是当事情出现问题时。有意识地在团队中建立信任系统。
- 让每个人的工作都可访问且可发现,以打破“工具”孤岛;
- 创建数据管道和沿袭的透明度,以便每个人都可以查看并解决问题;
- 建立监控和警报系统,以便在出现问题时主动了解情况;
使用DataOps角色来运营DataOps
如今,每个其他领域都有一个专注的支持功能,以帮助该功能高效且成功。例如,销售运营和销售支持专注于提高销售团队的生产力、提升时间和成功。 DevOps和开发人员生产力工程团队专注于改善软件团队之间的协作和开发人员的生产力。为什么我们的数据组织没有类似的功能?
DataOps职能可帮助组织的其他部门从数据中实现价值。此职能不执行数据或分析项目。相反,它侧重于工具、流程、自动化和文化,从而帮助组织的其他部分从数据中获取价值。
DataOps的消费者包括以下几部分:

构建DataOps职能
理解数据运营团队的最佳方式是通过类比其他团队:例如,收入运营团队激活收入数据以提高收入增长,产品运营团队激活产品数据以构建更好的产品。
数据运营是一项核心职能,可为组织的其他部门提供支持。有两个关键人物角色:
数据运营赋能主管:他们理解数据和用户,并且擅长跨团队合作和团结人们。数据运营启用主管通常来自信息架构师、数据治理经理、图书馆科学、数据策略师、数据布道者,甚至外向的数据分析师和工程师等背景。
数据运营赋能工程师:他们是数据运营团队中的自动化大脑。他们的关键优势是对数据以及数据如何在系统/团队之间流动的深入了解,既是自动化的顾问,也是执行者。他们通常是前开发人员、数据架构师、数据工程师和分析工程师。
DataOps团队激活“描述数据的数据”(又称元数据)来帮助组织从数据中实现价值。
Active metadata是实现DataOps梦想的关键
在这个日益多样化的数据世界中,元数据掌握着通往难以捉摸的乐土的钥匙——单一事实来源。团队的数据基础设施中总会有无数的工具和技术。但通过聚合所有不同的元数据,团队最终可以统一有关所有工具、流程和数据的上下文。
所有这些新形式的元数据都是由实时数据系统创建的,有时是实时创建的。这导致元数据的大小和规模呈爆炸式增长。元数据本身正在成为大数据。
在过去的几个月里,data mesh、data fabric和DataOps等概念得到了越来越多的发展。然而,所有这些概念从根本上来说都是基于能够收集、存储和分析元数据。随着元数据的增加以及我们可以从中获取的情报的增加,它可以支持的用例数量也在增加。如今,即使是最数据驱动的组织也只触及了元数据的皮毛。但充分利用元数据的潜力可以从根本上改变我们数据系统的运行方式。
对于这种新范式,元数据正在接近“大数据”,并且元数据的用例正在从简单的数据编目和治理发展到自动化和编程用例以支持 DataOps 和数据网格,处理元数据的旧方法已不再足够。
“The increased demand for orchestrating existing and new systems has rendered traditional metadata practices insufficient.”
— Gartner, Market Guide for Active Metadata Management
传统意义上说,数据目录是被动构建的。他们将来自许多不同工具的元数据引入“数据目录”或“数据治理工具”。这种方法的问题在于,它试图通过添加一个孤立的工具来解决“太多孤岛”问题。用户采用率受到影响,元数据停滞不前,这些令人兴奋的目录变成了昂贵的货架。
Active metadata改变了这一点。Active metadata不是仅仅从堆栈的其余部分收集元数据并将其带回被动数据目录,而是使元数据的双向移动成为可能。它将丰富的元数据发送回数据堆栈中的每个工具,随时随地为人们提供数据上下文——例如在BI工具中,当他们想知道指标的实际含义时,在Slack中,当有人发送数据资产的链接时,在查询编辑器中尝试找到正确的列,在Jira中为数据工程师或分析师创建票证。
Active metadata还可以通过自动化实现大量的编程用例——例如通过自动清除低质量或过时的数据产品来进行数据弃用,或者通过在检测到数据质量问题时自动停止下游管道并使用过去的记录来预测出了什么问题并在无需人工干预的情况下进行修复来进行数据质量管理。
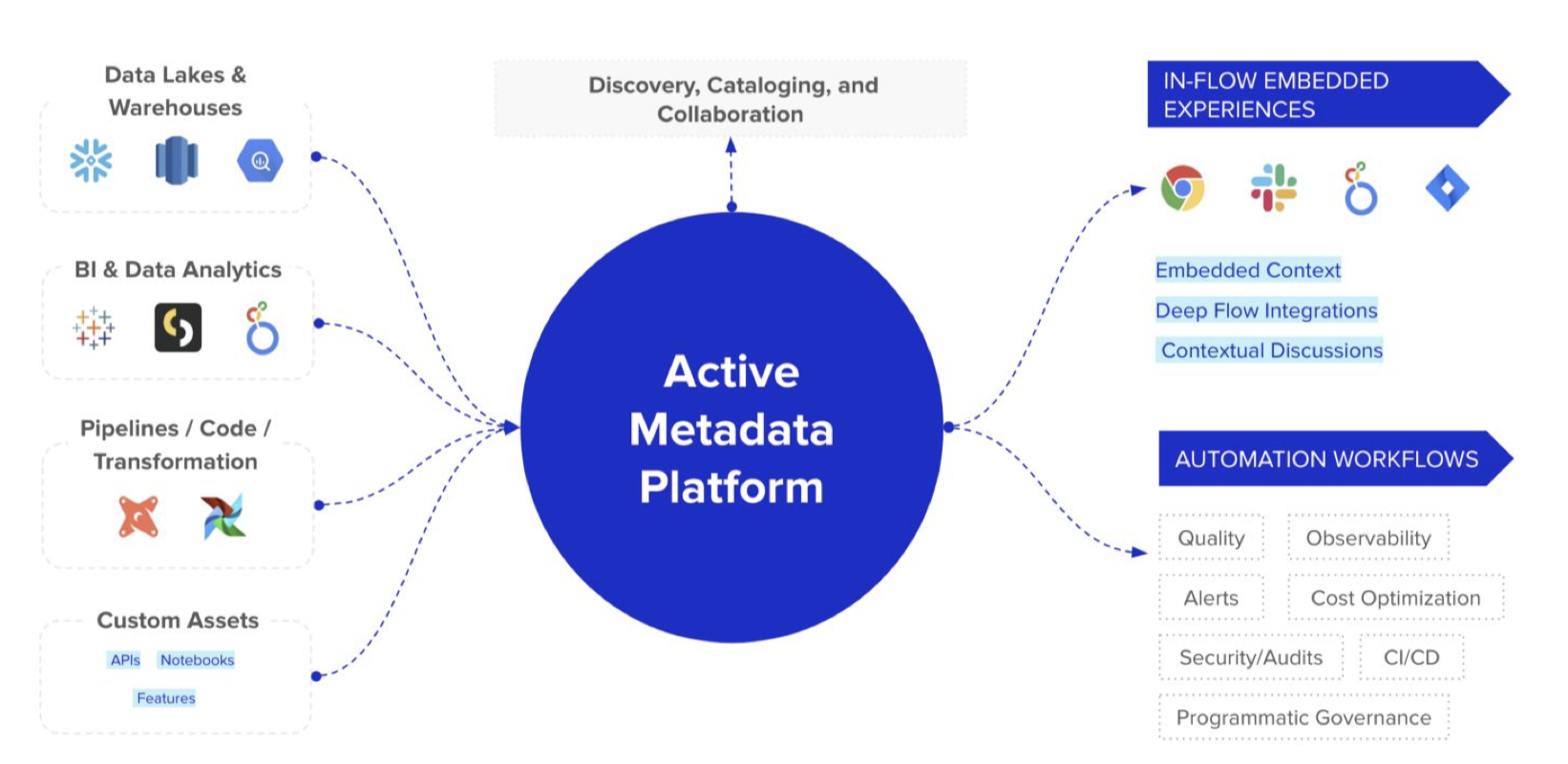
Active metadata平台的三个特征
孤立的工具 → 嵌入式协作
当我有问题时,我最不想做的就是跳转到另一个工具,找到我的登录信息,搜索仪表板,并查看数据血统。我想在我需要的时候,就在我所在的地方得到上下文信息。
想象一个世界,数据目录不再存在于它们自己的“第三方网站”中。相反,用户可以在他们需要的地方获取所有上下文信息——无论是在BI仪表板或者他们已经在使用的任何工具中,无论是Slack,Jira,查询编辑器,还是数据仓库。
从通用体验到个性化体验
数据团队是多样的。分析师、工程师、科学家和架构师都有他们自己的偏好。数据工程师关心的是数据管道的健康和数据质量测试,而分析师则关心列描述和频率分布。但是,被动的元数据工具却以相同的通用体验对待我们所有人。类比Netflix可以为你我提供个性化的体验,那么为什么要为所有的数据人提供相同的通用体验呢?所以不同数据角色的体验也应该是不同的。
从封闭&手动到开放&自主
元数据也将成为解锁现代数据堆栈中新超级能力的关键,例如根据需求自动调整管道或根据使用元数据自动弃用未使用的数据资产。



文章评论